Example Workloads
In addition to hand-rolled CUDA code, juice supports third party frameworks like PyTorch and TensorFlow. Using external code also comes with performance implications. In general, for deep learning frameworks: the more useful work the gpu does before having to report back to the host the more efficiently juice will perform. We can see this right away by comparing the single epoch timings for training some simple neural networks and one moderate complexity network:
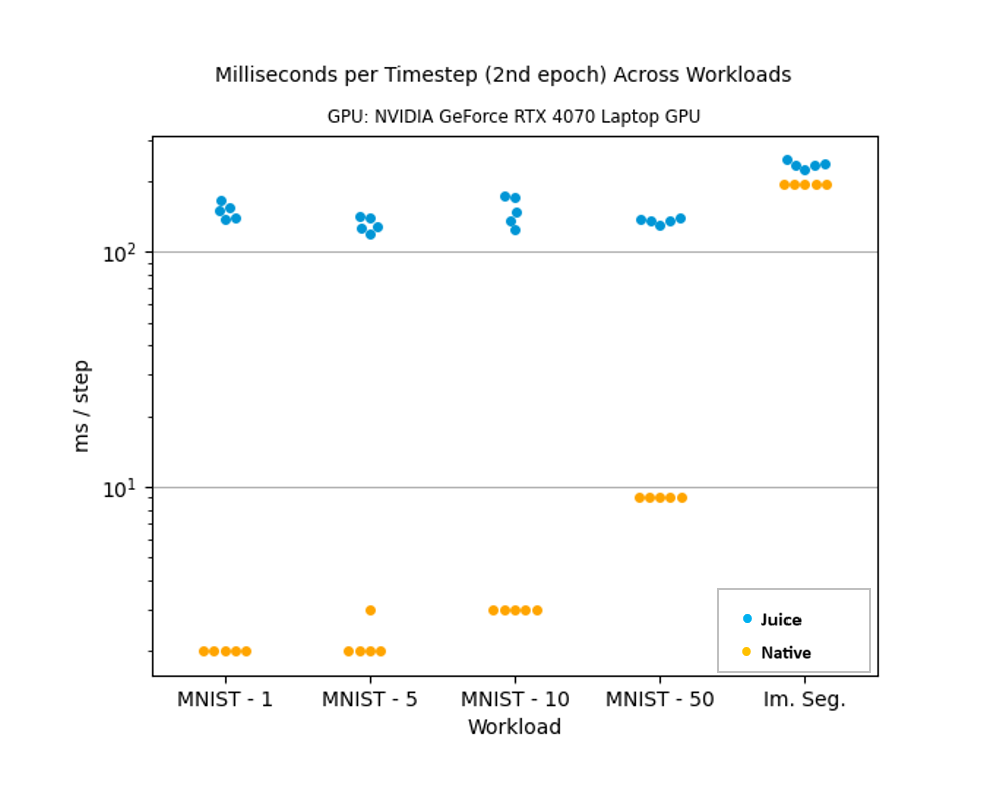
The MNIST-X workloads are composed of X simple dense layers applied in sequence to a small-sized dataset of images. Dense layers are often implemented as a single matrix multiplication performed on the GPU which amounts to very little actual work being performed. This results in the latency overhead being poorly hidden. The Image Segmentation (Im. Seg.) workflow runs a network that utilizes much more complicated layers and can therefore hide the overhead much better. To produce the above figure each network was trained for two epochs and the second epoch timing was reported to avoid any “warm-up” artifacts. This was repeated five times to avoid any network related hiccups.
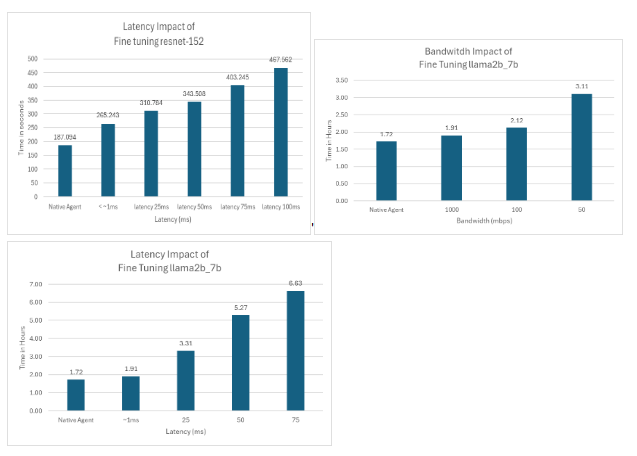
Further examples of the impact of latency and bandwidth on larger networks:
-
Client - AMD EPYC 7413, 8 CPUs, 32GB ram
-
Server - AMD EPYC 7413, 8 CPUs, 32GB ram, NVIDIA A40 48GB
-
Latency between Client <-> Server, 0.6ms
| Model Name | Mode | Average Time | juice as % of Native |
|---|---|---|---|
| EleutherAI/pythia-70m-deduped | Native | 6.471998405 | |
| EleutherAI/pythia-70m-deduped | juice | 6.703869677 | 96% |
| EleutherAI/pythia-6.9b-deduped | Native | 41.1083591 | |
| EleutherAI/pythia-6.9b-deduped | juice | 37.7191237 | 109% |
| EleutherAI/pythia-12b-deduped | Native | 60.10230432 | |
| EleutherAI/pythia-12b-deduped | juice | 54.84337864 | 109% |
# listing 1
#include <array>
#include <chrono>
#include <cmath>
#include <cstdlib>
#include <cuda_runtime_api.h>
#include <driver_types.h>
#include <iostream>
#define N 50000
#define NSTEP 1000
#define NKERNEL 1000
#define TIC auto start = std::chrono::high_resolution_clock::now();
#define TOC(msg) \
auto end = std::chrono::high_resolution_clock::now();\
std::chrono::duration<double> duration = end - start;\
std::cout << msg << " elapsed: " << duration.count() << "s" << std::endl;
__global__ void shortKernel(float * dst, float * src){
int idx=blockIdx.x*blockDim.x+threadIdx.x;
if(idx<N) dst[idx]=1.23*src[idx] + 4.0;
}
int main(int argc, char* argv[]) {
cudaStream_t stream{};
cudaStreamCreate(&stream);
float *devSrc, *devDst;
cudaMalloc(&devSrc, N * sizeof(float));
cudaMalloc(&devDst, N * sizeof(float));
int threads = 512;
int blocks = std::ceilf((float)N / threads);
{
TIC
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(devDst, devSrc);
cudaStreamSynchronize(stream);
}
}
TOC("Naive")
}
{
TIC
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(devDst, devSrc);
}
cudaStreamSynchronize(stream);
}
TOC("Interleaved")
}
{
TIC
bool graphCreated=false;
cudaGraph_t graph{};
cudaGraphExec_t instance{};
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(devDst, devSrc);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}
TOC("Graph")
}
cudaDeviceReset();
return 0;
}
# listing 2
const int batchesInFlight = 8;
std::array<float *, batchesInFlight> devSrcs{};
std::array<float *, batchesInFlight> devDsts{};
std::array<cudaEvent_t, batchesInFlight> events{};
std::array<int, batchesInFlight> stepsTaken{};
for (int i = 0; i < batchesInFlight; ++i) {
cudaMalloc(&devSrcs[i], N * sizeof(float));
cudaMalloc(&devDsts[i], N * sizeof(float));
cudaEventCreate(&events[i]);
stepsTaken[i] = 0;
}
{
TIC;
bool graphCreated=false;
bool batchesProcessing=true;
std::array<cudaGraph_t, batchesInFlight> graphs{};
std::array<cudaGraphExec_t, batchesInFlight> instances{};
for (int i = 0; i < batchesInFlight; ++i) {
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(devDsts[i], devSrcs[i]);
}
cudaStreamEndCapture(stream, &graphs[i]);
cudaGraphInstantiate(&instances[i], graphs[i], NULL, NULL, 0);
}
while (batchesProcessing) {
batchesProcessing = false;
for (int i = 0; i < batchesInFlight; ++i) {
if (stepsTaken[i] < NSTEP) {
batchesProcessing = true;
if (cudaEventQuery(events[i]) == cudaSuccess) {
stepsTaken[i]++;
cudaGraphLaunch(instances[i], stream);
cudaEventRecord(events[i], stream);
}
}
}
}
cudaStreamSynchronize(stream);
TOC("Pipes");
}
Help Improve This Page
Found a mistake? Want to contribute? Edit this page on GitHub or explore more editing options.