Example
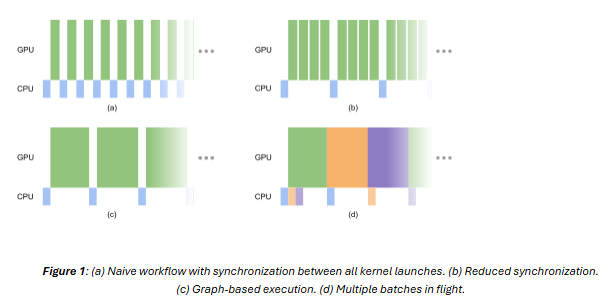
Let’s see how juice performs on a simple benchmark modeled after this NVIDIA blog post introducing the CUDA Graph API. The author takes a fairly simplistic workflow that consists of a single small kernel doing minimal work repeatedly applied to a buffer of data. The author starts with a naive implementation that performs a manual synchronization call after each kernel invocation, then refactors to an approach with synchronization calls only performed after a batch of kernels are executed. Finally, they introduce the graph API which allows for CUDA calls to be recorded and replayed with a single function invocation. These approaches, as well as another improvement are diagrammed in figure 1.
When the simple kernel is run in a batch of 1000 executions repeated 1000 times, we see the following performance from the native execution vs with juice:
| Native [seconds] | juice [seconds] | Slowdown | |
|---|---|---|---|
| Naive implementation | 6.94 | 54.93 | 691% |
| Reduced synchronizing | 4.06 | 8.79 | 116% |
| Graph-based execution | 3.52 | 3.70 | 5% |
Naively implemented, the existence of cudaStreamSynchronize calls after each kernel launches. This means that each subsequent kernel is not launched until the previous one completes.
For us, cudaStreamSynchronize stalls until the state of the stream on the client matches the state on the server. Natively, CUDA does the same thing, however for juice, since the latency is variable and dependent on network performance, this stall can take a longer time to resolve. We need to wait for the device to flush and synchronize itself alongside whatever subtle latency is introduced by the chatter between server and client. E.g. on a 70ms latent connection, a naively placed cudaStreamSynchronize is effectively a 70ms sleep. If the GPU operation extends beyond this 70ms, the performance impact won’t be noticeable. When the GPU is not sufficiently saturated this call will become a bottleneck.
This overhead is neatly addressed (locally and remotely) through the graph API which takes those thousand kernel launches and wraps them into one invocation that allows juice to make fewer round trip calls to the server. The goal here is to fully saturate the GPU, always.
Another means of hiding latency is to interleave multiple independent jobs. Assume that we need to complete eight independent tasks of the workload from the article and that we have sufficient memory to store all runs together. Rather than simply running our routine eight times in a row we can take advantage of CUDA events and queue up multiple batches of work at a time.
A rough sketch of the algorithm would be to schedule a graph launch (cudaGraphLaunch) on a CUDA stream followed by recording an event (cudaEventRecord) for each of our tasks. Once enough work is queued onto a stream we can query the events and queue new batches as the old ones complete. The advantage of this system is that the GPU can continue to do meaningful work while the CPU manages task state. Extending our reference code from the previous example to interleave eight jobs (listing 2) we observe an execution time of 27.78 seconds natively and 28.16 seconds with juice. This corresponds to a slowdown of only 1.4%. Additionally, both runtimes complete in less time than it would take to simply run the workflow eight times. This concept could (and likely should) be extended to a dynamic pool that can dispatch enough work to saturate the GPU while keeping the memory footprint manageable.
Help Improve This Page
Found a mistake? Want to contribute? Edit this page on GitHub or explore more editing options.